A walk through generative AI & LLMs: prospects and challenges

Author: Carlos Salas Najera
Following up on a previous article on ChatGPT prompting for Equity Research, this article briefly discusses the main prospects for Generative AI with a particular focus on providing a reader-friendly but comprehensive introduction to LLMs (Large Language Models) including the opportunities and challenges that come with them and the many ways of implementing LLMs in an investment organisation.

Generative AI Definitions
Wikipedia’s entry for Generative AI is rather tepid: “Generative artificial intelligence (AI) is artificial intelligence capable of generating text, images, or other media. Generative AI models learn the patterns and structure of their input training data and then generate new data that has similar characteristics”.
Alternatively, we can ask ChatGPT to provide a definition of Generative AI that is tailored for different audiences:

The jargon of AI-related terms continues to grow and can sometimes confuse readers at the very beginning of their Data Science journey with buzzwords such as AI, Generative AI, NLP and LLMs. In a nutshell, AI is the overarching field that encompasses a wide range of techniques and applications, while Generative AI focuses on data generation. It’s powered by very large machine learning models that are pre-trained on vast amounts of data, commonly referred to as foundation models (FMs). NLP (Natural Language Processing) is a subset of AI specifically concerned with language-related tasks, and LLMs are a type of NLP model known for their language generation capabilities, often powered by deep learning techniques. These concepts are interconnected, and advancements in one area often benefit others, leading to significant progress in the broader field of AI.
Because of space constraints, I recommend the readers to visit the next links by IBM and Nvidia to have a more detailed introduction about Generative AI.
In this article our focus will be LLMs (Large Language Models), which are models that blend the best of both the Generative AI and NLP worlds.
LLMs Introduction
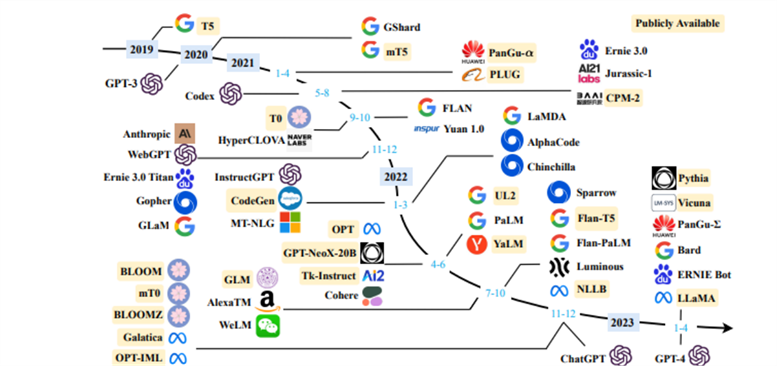
LLMs (Large Language Models) have revolutionised the field of NLP due to their ability to handle various language-related tasks effectively by leveraging deep learning and big data. The evolution of LLMs has not occurred overnight but is the result of many decades of research as pointed in the next timeline (source: author).

After many models and iterations, it was the rise of the Transformer Architecture in the last decade that allowed NLP to dramatically leap forward with models like BERT and its finance-specific versions like FinBERT, introduced in 2019. By the turn of the 2010s, the golden age of LLMs had begun with a zoo of LLMs being introduced in the NLP arena by many parties such as OpenAI (GPT), Google (Bard) or Meta (LLaMA) as can be seen in the chart below (source: A Survey of LLMs).
These state-of-the-art models leverage Transformer Architecture, Transfer Learning and Reinforcement Learning in two stages - pre-training and fine-tuning - to reach astounding performance across a diverse number of tasks like text generation, transcription, debugging, translation and summarisation among many others:
- Pre-Training:in this stage, LLMs are trained using large datasets for specific completion tasks (e.g. predicting missing words) or the generation of contextually relevant text. This training stage allows them to learn generalist patterns and nuances that are learned by the weights and biases of the model’s architecture. That said, the learned coefficients in this stage are not optimised for any particular task.
- Customisation: this part can be either performed using either “prompt learning” or “supervised fine-tuning”. In any case, these is the stage where the pre-trained model is altered in order to make it excel at particular tasks (e.g. sentiment analysis) within a specific domain (e.g. finance).
Overall, these LLMs share similarities in their foundational concept but also diverge in terms of their specific model architecture and the corpus data utilised during their pre-training stage. To illustrate this fact, the next chart (source: A Survey of LLMs) showcases the differences across multiple LLMs with models like GPT and LLaMA models being trained mostly with web content, yet the former being much more complex with +175bn parameters compared to the latter’s +65bn parameters. Other models like LLaMA and Chinchilla have a similar complexity as measured by their number of parameters, yet their pre-training corpus datasets are significantly different with Chinchilla relying much more on Books & News data (40%) and less in web content (56%). Overall, domain-specific LLMs have showed better performance than generic models for specific tasks, yet generic data is still important for LLMs to be able to extrapolate and think “out-of-the-box”.

The reader can visit a more detailed explanation about GPT model specs in this first article on LLMs focused on ChatGPT3 prompting.
LLMs Customisation: Prompt Learning vs Fine-Tuning
In the context of explaining model customisation of LLMs, it's important to understand the distinction between the foundational model and a customised model. On the one hand, the foundational model refers to the original, pre-trained Large Language Model (LLM) that has been trained on a vast and diverse corpus of text data e.g. GPT-3. Remember that the foundational model is designed to be a general-purpose language model that can handle various NLP tasks without any specific fine-tuning.
On the other hand, a customised model is created by either adding incremental knowledge or skills, or by including domain-specific knowledge (e.g. finance) to the foundational model. That results in a customised model that is more specialised and optimised for a specific use case e.g. BloombergGPT.
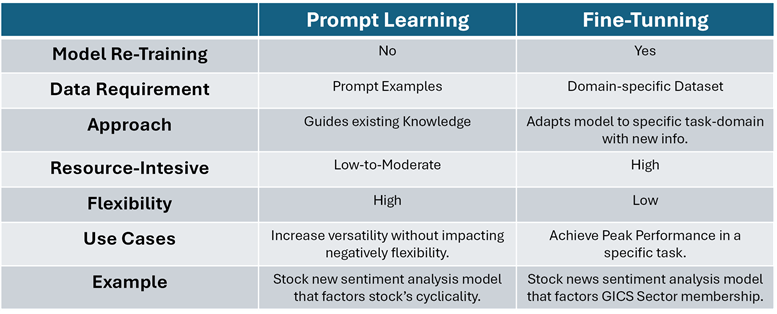
But let’s circle back to our original question: what is the difference between “prompt learning” and “fine-tuning” when customising a foundational LLM? In a nutshell, “prompt learning” is used when adding incremental or new skills to a foundational model is desired; whereas “fine-tuning” is a more resource-intensive customisation technique that retrains the model with a domain-specific dataset that ultimately changes the behaviour of the model dramatically.
“Prompt learning” is a technique used to guide the behaviour of a pre-trained LLM by providing explicit instructions or prompts in the input text. Instead of fine-tuning the model on a task-specific dataset, prompt learning relies on designing well-crafted input prompts that serves as a guide to elicit the desired response from the model without requiring extensive retraining. Some well-known techniques for prompting are:
- Zero Shot Learning: Asking the foundation model to perform a task with no previous example or knowledge. This is simply using the foundation model without any “prompt learning”.
- Few Shot Learning: builds upon “zero-shot” learning by allowing the model to observe a small amount of task-specific examples during inference. Few-shot learning provides a way to adapt a pre-trained model to specific tasks with minimal examples.
- P-tuning: Training a "prompt-model" with a much larger number of examples (+100s, +1000s) covering various scenarios and desired responses that get sent to the foundation model at inference time. P-tuning allows for more controlled adaptation of the model's behaviour while preserving its general language understanding.
- Constrained Generation: additional constraints or requirements are provided to guide the output. For example, you could instruct the model to generate a coherent paragraph while including specific keywords or concepts to match a certain predefined criteria.
- Dialogue management: guides a LLM's responses in a conversation by providing prompts that instruct the model on how to respond to user inputs. This can help in creating more contextually relevant and meaningful interactions.
- RAG (Retrieval-Augmented-Generation): this approach was introduced by Facebook AI Research (FAIR) and collaborators in 2021 and is a powerful prompting technique used by Bing search and other high-traffic sites to incorporate current data into their models. Using RAG in an AI-based application involves the following steps:
- The user inputs a question.
- The system searches for relevant documents that might answer the question (e.g. proprietary data stored in a document index).
- The system creates an LLM prompt that combines the user input, the related documents, and instructions for the LLM to answer the user’s question using the documents provided.
- The system sends the prompt to an LLM.
- The LLM returns an answer to the user’s question, grounded by the context we provided.
“Fine-Tuning”, often referred as “Transfer Learning” or “Supervised Fine-Tuning”, involves taking the pre-trained foundational model, often referred to as a “base model”, to conduct further training using a smaller, task-specific dataset. During fine-tuning, the model's weights and parameters are updated based on the task-specific data, allowing the model to adapt its knowledge to the specific task (e.g. sentiment analysis) or domain (e.g. investments). Fine-tuning is usually a supervised learning process where the model is provided with labelled examples,and it learns to make predictions or generate text according to the task requirements. In this stage, techniques such as learning rate scheduling and regularisation are used to refrain the model from overfitting on the specific task while preserving its generalist knowledge.
The next table highlights the main differences between “Prompt Learning” and “Fine-Tuning” along with use cases and a simple example (source: author).
Overall, RAG has become relevant as a prompting technique based on research evidence as it’s more cost-efficient and straightforward to implement than model fine-tunning, especially when coupledwith services such as Azure Cognitive Search that facilitate the search of documents. In particular, using RAG with vector search allows to encode the input (user question and required documents) using a pre-trained embedding model such as OpenAI’s “text-embedding-ada-002” and a pre-trained LLM e.g GPT model. The next illustration displays this process very clearly (source: Microsoft):

NLP Models for Finance: Evolution, Opportunities and Challenges
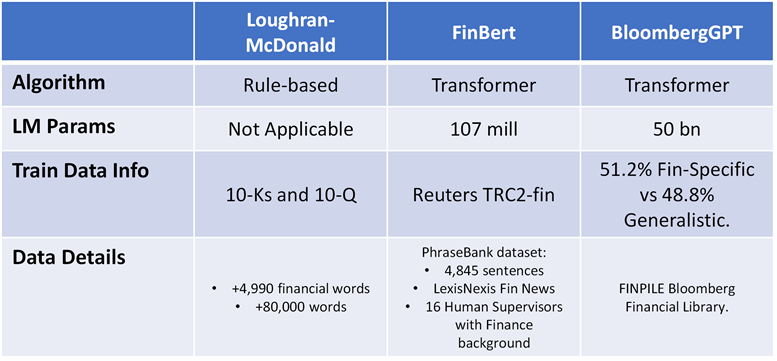
The NLP revolution has also arrived in finance over the last decade, starting with very simplistic models that applied rule-based word-dictionary algorithms using 10-K and 10-Q information as training corpuses such as Lougrhan-McDonald . The advent of Transformer architecture came with the introduction in 2019 of FinBERT, a Finance-focused version of BERT models. Last but not least, LLMs have also started to be implemented in the investment industry e.g. introduction in 2023 of BloombergGPT, a GPT model with +50bn parameters and corpus data focused on finance-specific categories.
As discussed in the section “Generative AI Prospects”, there are many opportunities for investment organisations that are actively implementing LLMs tools within their organisation’s workflow. That said, the benefits of LLMs are more visible and easy to measure in some tasks such as customer service (e.g. customer service bots) or automation (e.g. summarised conference call transcripts) than in others where validation is far more complex and, sometimes, not feasible as it happens in stock news sentiment analysis.
For instance, Lopez-Lira, Tang (2023) conducted a first exploratory approach with LLMs applied to sentiment analysis by using ChatGPT conducting news sentiment analysis to predict daily stock returns using CRSP data and news headlines for the period September 2021 to December 2022. To avoid overfitting and look-ahead bias, the version of ChatGPT used by the authors had been trained only until September 2021. The authors use the following standardised prompt in their study along with the next mapping applied to ChatGPT’s answers: “YES” is mapped to 1, “UNKNOWN” to 0, and “NO” to -1.:

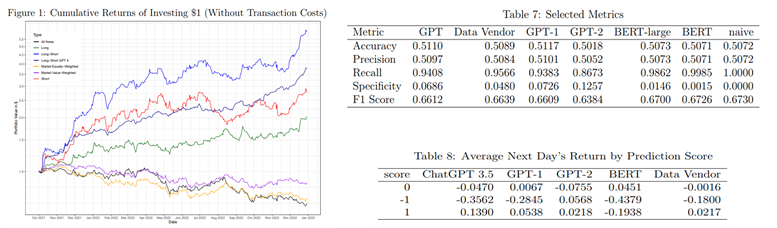
ChatGPT scores were averaged on a given day and logged to assess stock returns predictability. Furthermore, the authors followed a conservative update approach as news released after the closing bell were incorporated in the opening of the next day. Using these signals, the authors create several long-short portfolios using the ChatGPT model (GPT in the table) and other models such as GPT2, GPT1, BERT and sentiment signals from a data vendor reaching the next conclusions:
- ChatGPT (GPT using version 3.5) scores display statistical significance predicting daily stock returns. Although ChatGPT showcases a similar performance to other models with regards to ML model performance metrics (e.g. Accuracy, Recall, F1, etc); where it actually excels is in return predictability i.e. more basic models such as GPT-1, GPT-2, and BERT cannot accurately forecast returns, indicating return predictability is an emerging capacity of complex LLMs.
- ChatGPT outperforms traditional sentiment analysis methods from a leading data vendor. In other words, data vendors will be forced to enhance their sentiment models to pose a challenge for LLMs.
- Incorporating advanced LLMs into the investment decision-making process can yield more accurate predictions and enhance the performance of quantitative trading strategies.
- Predictability power is concentrated on smaller stocks and more prominent on firms with bad news, consistent with limits-to-arbitrage arguments rather than market inefficiencies.
A more recent analysis by Glasserman, Lin (2023) unveiled the so-called “distraction effect”, in which general knowledge of the companies named interferes with the measurement of a text's sentiment. The authors found that anonymised headlines (removing a company’s name or identifier) provided better sentiment classification and predictive properties both in-sample and out-of-sample.
That said, extreme caution is recommended when extrapolating these preliminary results as the short time period of the analysis is limited by the lack of capacity to the authors to pre-train a model in multiple points in the past due to budgetary and logistical barriers acknowledged in the section “LLMs Economics”.
Along with the aforementioned issues, LLMs are not exempt from a wide variety of risks and challenges when implemented in the financial arena with some of the most important shown here:
- Inherent Biases: LLMs are trained with a dataset obtained from many sources (web, books, etc), thus it can learn biased behaviour and output biased answers. Luckily, the combination of models can allow ML engineers to conduct moderation tasks to constrain the output before it’s released.
- Laggard: LLMs are trained with data up to a specific date i.e. it might not be aware of recent events. Hence, those users using a LLM whose last fine-tuning was, for instance, one year ago should be aware that the model might not be prepared to deal with tasks that require knowledge of the latest developments.
- Hallucination:ChatGPT can provide false information, especially with complex topics. You can provide more context with either “few-shot” prompting or “p-tuning”.
- Security, Legal, Privacy & Ethical Issues: training datasets are made out of IP created by third parties, thus critics have denounced LLMs as a sophisticated tool for plagiarising. Other concerns such as security, legal, privacy or ethical issues are also present when using, for instance, client-sensitive information within a LLM application.
- Lack of consistency: ChatGPT provides multiple responses for the same question. Although LLMs like OpenAI’s GPT allow users to modulate the degree of deterministic behaviour in the model’s output - using the “temperature” argument to switch from low to high deterministic model behaviour - recent research evidence has confirmed that results from LLMs can be highly unstable even when switching this “temperature” argument to 0 to minimise non-deterministic behaviour (source: Non-determinism of ChatGPT in Code Generation).
- Expensive: training, fine-tuning or even the deployment of “ready-to-use” LLMs requires a proper cost-benefit analysis before an investment organisation decides to add LLMs as part of its investment process. The cost of LLMs is the main focus of the next section.
LLMs Economics
A difficult question to answer is how feasible it is to carry out LLM research in-house for the average investment firm. To calculate a reasonable budget estimate, it is necessary to conduct thorough due diligence about multiple factors. These include the specific purpose of the model, data requirements, required computing power and the estimated number of requests among many others.
Some helpful insights to explore the cost of developing an in-house LLM are shown below:
- Training a 40Bn GPT model with 300Bn tokens requires 33 days with 160 GPUs A100 in DGXSuperPOD infrastructure (source: Nvidia).
- According to the report “How much computing power does ChatGPT need”, the cost of a single training session for GPT-3, a +175bn parameter model, is estimated to be around $1.4 million, and for some larger LLMs, the training cost ranges from $2 million to $12 million (source: techgoing.com)
- For instance, Meta’s largest LLaMA model with +65bn parameters used 2,048 Nvidia A100 GPUs to train on 1.4 trillion tokens (750 words is about 1,000 tokens), taking about 21 days tantamount to 1 million GPU hours to train, which rises the total cost to +$2.4 million using dedicated prices from AWS.
- Extrapolating the previous results, the total training cost of the finance-specific BloombergGPT model (+50bn params) could be in the region between $1.2 million to $1.8 million (source: author).
Several recent developments have cheapened LLM training and fine-tuning such as LIGO (Linear Growth Operator), a novel technique to reduce the LLM training computational costs by half, or the recent cut in rates by OpenAI.
That said, even when taking into consideration these positive developments, in-house training of LLMs continues to be an unfeasible feat for most players in the investment industry, with the exception of top-tier firms in the banking, hedge fund and asset management arenas.
As a result, the only feasible alternative for the average investment firm is to rely on customised pre-trained models for specific tasks (prompt learning or fine-tuning), or buy NLP signals from competitive vendors. With regards to the latter option, data vendors might have to consolidate or enter into R&D joint venture deals in order to build-up financial muscle to increase their R&D investment in LLMs in order to enhance their NLP models and avoid being left behind by the customised models created by their clients.
As an illustration of efficient LLM usage within an asset management organisation using ChatGPT prompting, which is a foundational model with no finance-specific customisation, the next example is provided where a hedge fund wants to develop an internal sentiment analysis tool that allows them to generate signals from conference call transcripts. The following assumptions must be considered:
- ChatGPT prompts are used to generate trading signals based on conference call transcript output.
- Prompt limit override with transcript sections i.e. each transcript is divided into 3 sections that require individualised model requests: “Business Performance”, “Business Outlook”, and “Q&A section”. For the record, NLP research shows that the latter section is the most important to generate insights.
- Average conference call transcript length is ~7,000 words, tantamount to 9,333 tokens per transcript. Remember 100 tokens is approximately 75 words.
- Universe of 6,000 stocks with quarterly calls is equivalent to 168 mill words, which is a figure obtained from the product between 7,000 words per transcript, four quarters per stock, and a total universe of 6,000 stocks.
- OpenAI pricing used has been $0.03 per 1,000 tokens for prompts and $0.06 per 1,000 tokens for output.
Based on OpenAI pricing, the estimated cost would be as approximately as low as $7,000 per annum should the application only send 1 prompt per transcript focusing on the Q&A section only. However, it could be as much as $21,000 per annum based on 3 prompts per transcript that include all the sections such as Business Performance, Business Outlook, and Q&A section (source: author).
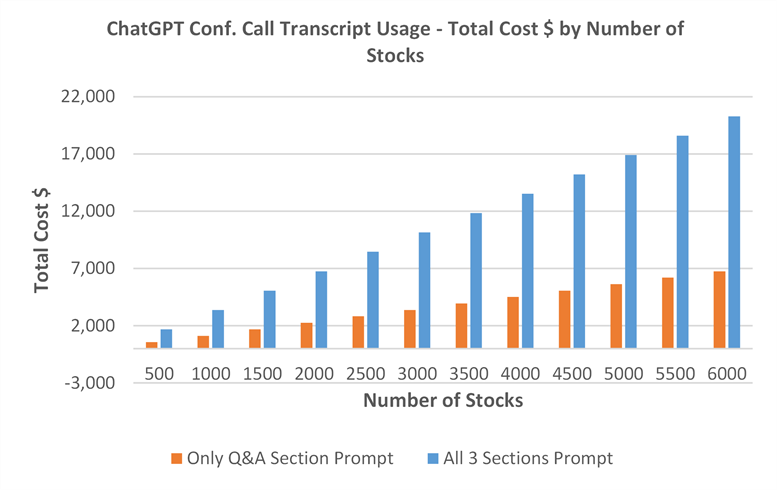
Remember, this will be the cost of an application that is not fine-tuning an LLM model in-house and that, most importantly, makes a limited amount of requests per annum per stock as it’s only dealing with conference call transcripts. Nevertheless, if our intention is to create a more ambitious LLM-driven tool to generate signals with daily news for our universe of stocks, you can see how the expected usage costs are going to boom into a figure that will not be achievable for many investment firms in the industry.
Generative AI Prospects
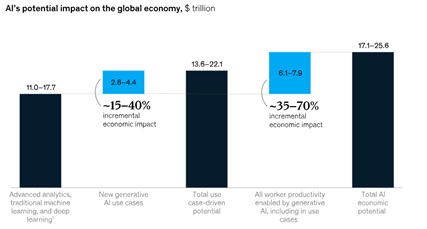
According to a study by McKinsey, Generative AI could add between $2.6 trillion and $4.4 trillion annually in terms of economic value, increasing the impact of all artificial intelligence by 15-40%. Here are some key takeaways:
- The bulk of the value that generative AI could deliver is focused on four areas: customer operations, marketing and sales, software engineering, and R&D.
- Generative AI has the potential to change the workplace with current applications allowing to save approximately two thirds of employees’ time today. Some estimates point towards half of today’s work activities being automated at some point between 2030 and 2060.
- In numbers, Generative AI could boost labour productivity growth by contributing 0.1%-0.6% annually through 2040.
- Contrary to the Industrial Revolution - where automation technologies had the most impact on workers with the lowest skill levels - Generative AI has the opposite effect by having the most incremental impact on more-educated workers and, as a result, white-collar jobs.
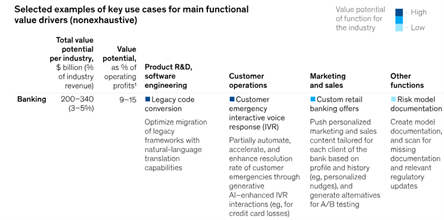
On an industry-by-industry basis, Generative AI’s impact depends on a variety of factors, such as the mix and importance of different functions, as well as the scale of an industry’s revenue. Some relevant industries that will be severely re-shaped in the coming decades are banking, retail and pharmaceuticals. Banking is particularly receptive to Generative AI as it will allow this industry to take on lower-value tasks in risk management e.g. reporting, regulatory monitoring or data collection. Some of the use cases from the same report are highlighted in the next table:
Conclusions
Generative AI has firmly established its presence, and is poised to revolutionise various sectors such as finance. Large Language Models (LLMs) are proving pivotal in this transformation according to their recent impressive performances. However, their widespread integration into industries might only lead to gradual progress. The investment sector faces challenges of inadequate expertise and notably, the substantial costs associated with in-house model training.
Consequently, investment enterprises will confront the choice of leveraging foundational models, customisable variants, or insights from NLP vendors who remain well-versed in the latest advancements of LLMs.
PIC and Links
L/S Portfolio Manager | Lecturer & Consultant
• https://www.linkedin.com/in/csalasls/
• https://twitter.com/CarlosSNaj

Related Articles
