
Author: Carlos Salas Najera
Multiple finance professionals have reached out over the last months via social media enquiring about how to become a Data Scientist. There is a perception, though, that they can achieve this within a year without prior coding experience and statistics knowledge.
Quick answer: Impossible.
This reply stirs up feelings of frustration, procrastination and sadness. The good news is that there is also a long answer: You can as long as you are fully committed in the long term.
Article Audience
This article is oriented towards individuals of any age and level of experience that want to learn data science and machine learning, but are confused about how or where to start. My objective here is to lay the foundation that can help those individuals in finding a realistic learning path to build a strong Data Science skill-set without knowledge gaps that could eventually create future concerns or, even worse, result in dropping out of the race.
Because of the vast amount of information to be covered, I have decided to focus this first article on a generalist view of the Data Science path. A second article - to be released in the coming months - will deal with finance-specific libraries available to Python and R users; as well as special Data Science topics that should be prioritised when dealing with investment problems such as imbalanced datasets or data issues.
The path proposed in this article assumes the reader is an absolute beginner in terms of coding and data science as well as working full-time. For those readers with some literacy in terms of coding or quantitative knowledge, please see the last section for further guidance about where to start.
No Shortcuts
Many finance professionals start learning Python using the pandas library for data analysis without any basic data science or base Python knowledge whatsoever. In other words, the individual starts learning advanced concepts without fully mastering essential coding building blocks such as data types, indexation or vectoriszation. This creates a knowledge gap that will compound in the future, creating an insurmountable glass-ceiling that might result in frustration, anger, despair, and finally, abandonment of the Data Science path. In other words, refrain from taking shortcuts in order to avoid future disappointment.
Discipline is Essential
Nobody believes a person can learn to speak a language fluently by only allocating two hours on a weekly basis. Nevertheless, a lot of individuals believe this is the case when learning Data Science.
A finance professional must prepare to invest time in the learning process. Full-time finance professionals willing to successfully learn Data Science should understand that a minimum commitment of 4 to 8 hours per week is essential for attaining their goal. For the record, the most successful data scientists spend at least 3 hours per day in their learning habits. Some topics might be more or less time-consuming and a weekly commitment is needed during at least 9 months per year.
Recommended Learning Path
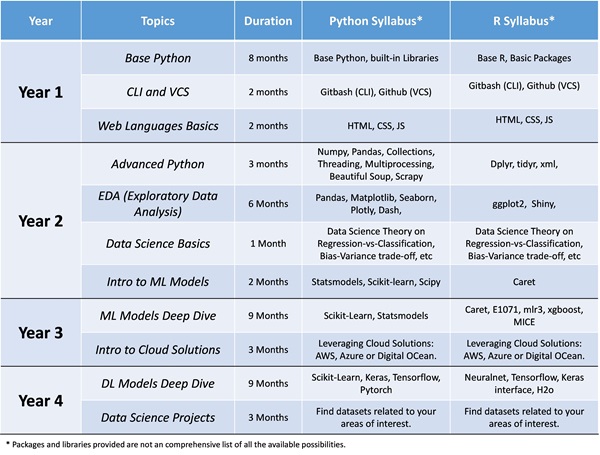
> Year 1: Deep Dive in Coding.
One piece of advice for absolute beginners: focus only on coding.
One of the most frequent reasons behind dropout rates in Data Science is coding frustration. Students with no coding experience whatsoever see the coding part as an insurmountable obstacle in their learning curve. The best way to confront this is to be patient and allocate as much time as possible to become fluent in either Python or R. If you choose Python, for instance, try at least to also become familiar with some basics of R; and vice versa. Whether you chose to master Python or R, you will have to allocate a minimum of 4 hours per week to master concepts such as data types, conditionals, user-defined functions, advance methods (lambda, map, etc) and classes.
In addition, there are some other skills that are essential for a Data Scientist to become productive such as CLI (Command Line Interface) or VCS (Version Control System). On the one hand, CLI allows you to become confident using a terminal for functional tasks such as managing environments or installing libraries; among many other tasks. On the other hand, VCS such as Github would allow you to learn how to stop using only local folders to store your projects and learn how to manage a project more efficiently, especially when part of a team.
Additionally, it is recommended that the individual becomes familiar with the basics of web development languages such as HTML, CSS, and Java Script. This will help the Data Scientist to understand later in Year 2 how web scrapping libraries work, or how to develop bespoke web applications.
Lastly, the book “Automate the Boring Stuff with Python”, can help the individual to put into practice a lot of base Python concepts acquired during the year.
> Year 2: Deep Dive Data Analysis.
One piece of advice for absolute beginners: Master Data Manipulation and Visualisation.
Start applying your basic coding skills in Data Science applications aimed at exploring visually multiple datasets. The development visual analytics for EDA (Exploratory Data Analysis) purposes is essential, which requires the mastering of important libraries like numpy or pandas. Another area where it worth allocating a couple of weeks of your time is to learn how to stream data using APIs, or web scraping information using libraries like BeautifulSoup, Scrapy or Selenium. A warning here is that you should become familiar with these web scraping libraries but beware web scraping can be a job by itself thus do allocate excessive time here unless your goal is to become a professional specialised in web scraping projects.
In addition, you should start becoming more familiar with advance programming concepts at this stage to boost your code efficiency such as compiling, threading, multiprocessing, and functional programming. Most importantly, the data scientist should be able to build notebooks that resemble an application so that, ultimately, they can learn to build apps using libraries like Dash in Python or Shiny in R Studio.
The second half of the year should be a good time to start introducing yourself to basic Data Science concepts such as regression-vs-classification, Bias-Variance trade off, types of ML models, Cross-Validation, and ML performance metrics; among many others. Moreover, another relevant area that is worth pursuing to prepare the new year is to start gaining some exposure to your first models, particularly focusing on simple parametric models such as Linear models (Linear Regression, Logistic, ARIMA, etc). This fact will allow the individual to get acquainted with important libraries such as scikit-learn, Scipy or Statsmodels, which will be used more intensively henceforth.
> Year 3: Deep Dive Machine Learning
One piece of advice for absolute beginners: Prioritise Intuition over Mathematical Details.
At this stage, you should be confident in your coding skills and ability to manipulate and visualise data. As a result, you are fully prepared to dive into the Machine Learning (ML) space and understand how to deal with a ML workflow including data pre-processing, data transformation, feature engineering, feature selection, hyperparameter optimiszation and cross-validation, and model generalisation. The main focus should be to dive deeper into supervised and unsupervised models i.e. intuition, mathematical details, exceptions, and hands-on coding experience.
A word of caution: ignore Neural Network (NN) models. I will repeat this once again. Ignore NN models. Focus on standard ML models such as tree-based (e.g. random forest), SVMs, KNNs, or Bayesian Models; among many others. At the end of this year- and once you fully understand and apply these vanilla models - you can start digging into vanilla introductory NN models such as MLP. A lot of students jumpy too quickly into the “ANN wagon” without properly understanding vanilla models or without having allocated time to research datasets with standard ML models. Standard ML models can teach you how to solve issues when dealing with real world data (e.g. imbalance datasets) that can be tremendously useful later when you try to understand how NN models work.
Last, but not least, it would be interesting to start exploring by year- end how to train models using not only your local computer, but also remote cloud servers from providers such as AWS, Azure or Digital Ocean. How to leverage cloud solutions will become a extremely useful skill in the future when analysying big data and applying DL (Deep Learning) models.
> Year 4: Deep Dive Deep Learning.
One piece of advice for absolute beginners: Do not use a sledgehammer to crack a nut.
ANN (Artificial Neural Networks), particularly Deep Learning (DL), have brought incredibly valuable breakthroughs into the investments industry, especially when applied to higher frequency data as well as NLP (Natural Language Processing) analysis. Nevertheless, DL models have also been a source of controversy branded as a marketing gimmick, since sometimes the data science problem at hand is a simple one that does not require model complexity to be solved efficiently. Likewise, the use of DL models with datasets whose properties are not adequate may bring along undesired model complexity and, ultimately, result in a spurious outcome.
Therefore, the data scientist must not only understand the intuition and mathematical detail of vanilla ANN and DL models such as CNN or RNN, yet also fully rationalise the situations when a specific data science problem requires a DL approach and when simpler tools are more suitable. A group of authors published a very fascinating paper in 2021 about this topic where they demonstrate that a window-based input transformation boosts the performance of a simple Gradient Boosting Regression Tree model to levels that outperform all state-of-the-art DL models.
> Year 5: Choose your Path.
This is another important step in your Data Science journey. At this stage you will probably realise that the more you know, the more you realise you do not know. You can be a finance professional in investments, compliance, trading, research, sales, business analysis, management, marketing, or any other position. In any case, you will have to choose to learn more about specific topics of Data Science depending on the career path you choose to professionally specialise.
As an illustration, a marketing or sales professional will be more interested in mastering visual analytics applications. Alternatively, an execution trader will be much more eager to acquire in-depth knowledge of DL models and Reinforcement Learning (RL) models to enhance an execution flow. In the same way, an investment analyst or portfolio manager will be especially interested in extracting investment insights more accurately using advanced ML models.
Python or R?
A never-ending debate in the Data Science community has been the language to choose: Python vs R. Although at the beginning of the last decade this was a close feud, Python began to become dominant over the second half of the decade for many reasons (source: stackoverflow.com).
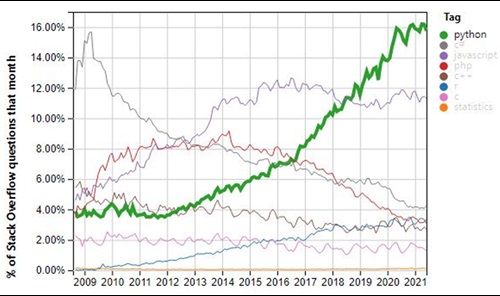
Firstly, Python is a more powerful language than R as the former is regularly used to scale up ML applications whereas the latter was never designed for this purpose. Secondly, Python also has more inherent capacity to deal with large datasets than R. Thirdly, R used to have a significant edge over Python in terms of the number of user-friendly available libraries to conduct statistical analysis, machine learning and visualisation. Nevertheless, Python has dramatically closed the gap since 2015 with many more projects and libraries available to the Python community.
Although I favour Python in my workflow, I vehemently recommend Data Science students to acquire basic knowledge of R for many reasons. For example, a finance professional with full knowledge of Python and some familiarity with R will be always more employable than one with only Python expertise. Likewise, a Data Scientist can find good ideas in the R community than could only be translated into Python if the developer is fluent in both languages.
Last Thoughts: DIY
Remember the recommended itinerary assumes an absolute beginner level of coding, computer science and basic statistical concepts as well as a full-time work with less time available for self-study. For instance, those already familiar with coding logic might only need to get used to the new syntax of Python and a few other differences; but this should take them less than 6 months. Best yet, those readers with full-stack coding experience may jump straightaway to the Year 3 planning.
Conclusion: No Free Lunch
There is no easy way to acquire a valuable skill-set such as Data Science, especially when one is an absolute beginner. Some experienced readers in data science could disagree with the length of my recommendations, yet I believe this is a solid, realistic and consistent plan for an investment professional to attain a solid level of data science skills.
As explained in the introduction, a future article will be covering finance-specific libraries that can make the life of investment professionals much easier, as well as several challenges investment professionals can come across when dealing with real world finance datasets. In the meantime, feel free to contact me should you have any questions about the proposed learning path.
Carlos Salas Najera, MSc, CFA, CQF, L/S Portfolio Manager, iLuminar AM.

